RDD: Retrieval-Based Demonstration Decomposer
for Planner Alignment in Long-Horizon Tasks


Abstract
To tackle long-horizon tasks, recent hierarchical vision-language-action (VLAs) frameworks employ vision-language model (VLM)-based planners to decompose complex manipulation tasks into simpler sub-tasks that low-level visuomotor policies can easily handle. Typically, the VLM planner is finetuned to learn to decompose a target task. This finetuning requires target task demonstrations segmented into sub-tasks by either human annotation or heuristic rules. However, the heuristic subtasks can deviate significantly from the training data of the visuomotor policy, which degrades task performance. To address these issues, we propose a Retrieval-based Demonstration Decomposer RDD that automatically decomposes demonstrations into sub-tasks by aligning the visual features of the decomposed sub-task intervals with those from the training data of the low-level visuomotor policies. Our method demonstrates superior performance compared to the state-of-the-art sub-task decomposer on both simulation and real-world demonstrations, showcasing robustness across various settings.
The Planner-Visuomotor Dataset Misalignment Problem
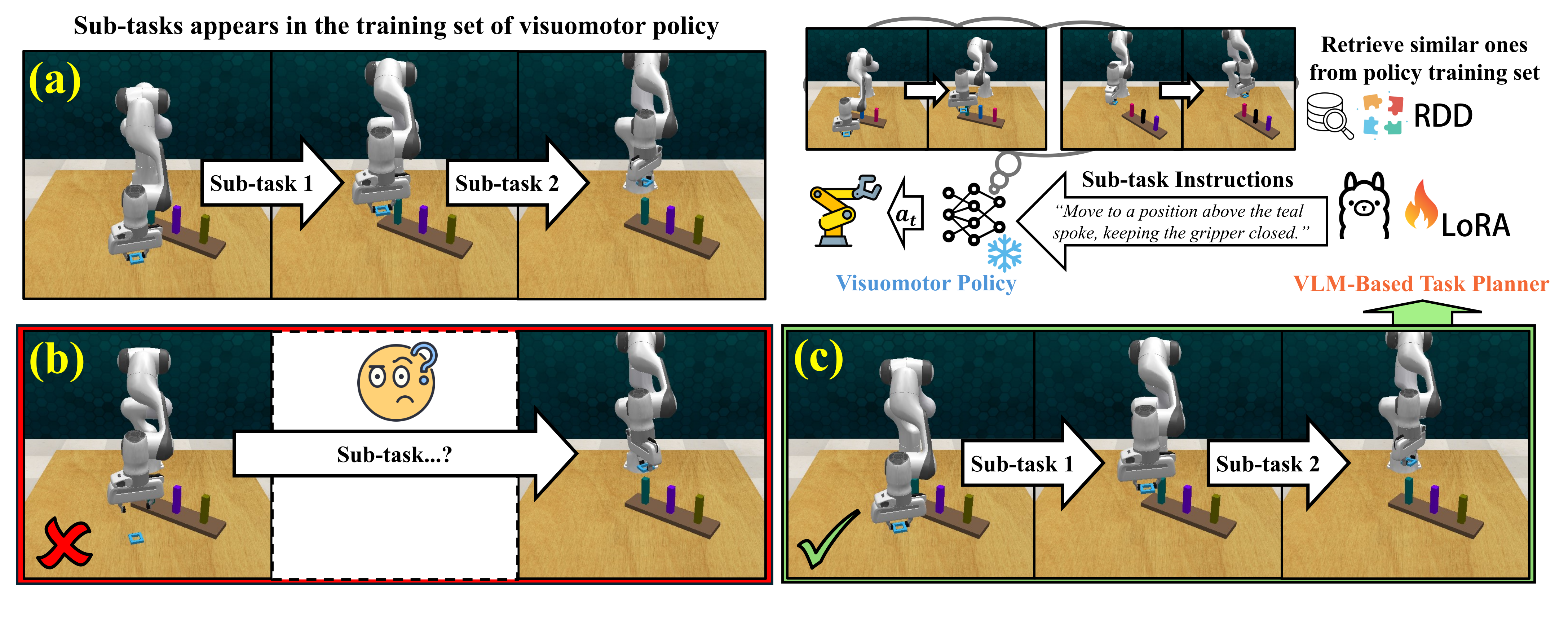
The planner-visuomotor dataset misalignment problem:
In hierarchical VLAs, the planner, often a powerful VLM, performs task planning and reasoning to break down complex tasks into simpler sub-tasks with step-by-step language instructions.
Conditioned on the generated sub-task instructions, a learning-based visuomotor policy, trained on datasets with short-horizon sub-tasks,
performs precise manipulation to complete the sub-tasks one by one, thereby completing long-horizon tasks.
A VLM planner typically needs to be finetuned with demonstrations of a given task, where
demonstrations are temporally decomposed to sub-tasks by human annotation or heuristics.
The planner-visuomotor dataset misaligning problem is illustrated in the firgure:
(a) Two sub-tasks appear in the visuomotor policy's training set, on which the
policy has been optimized.
(b) Existing sub-task decomposers, such as UVD,
use heuristic decomposition
rules and may generate "unfamiliar" sub-tasks that are difficult to handle for the low-level visuomotor policy.
Core idea of RDD:
As shown in (c),
RDD decomposes the demonstration into sub-tasks that are visually similar to the ones in the
training set of the visuomotor policy.
The sub-tasks are then used to finetune the high-level planner, which will generate
sub-task instructions that are "familar" to the low-level visuomotor policy.
Retrival-Based Demonstration Decomposer
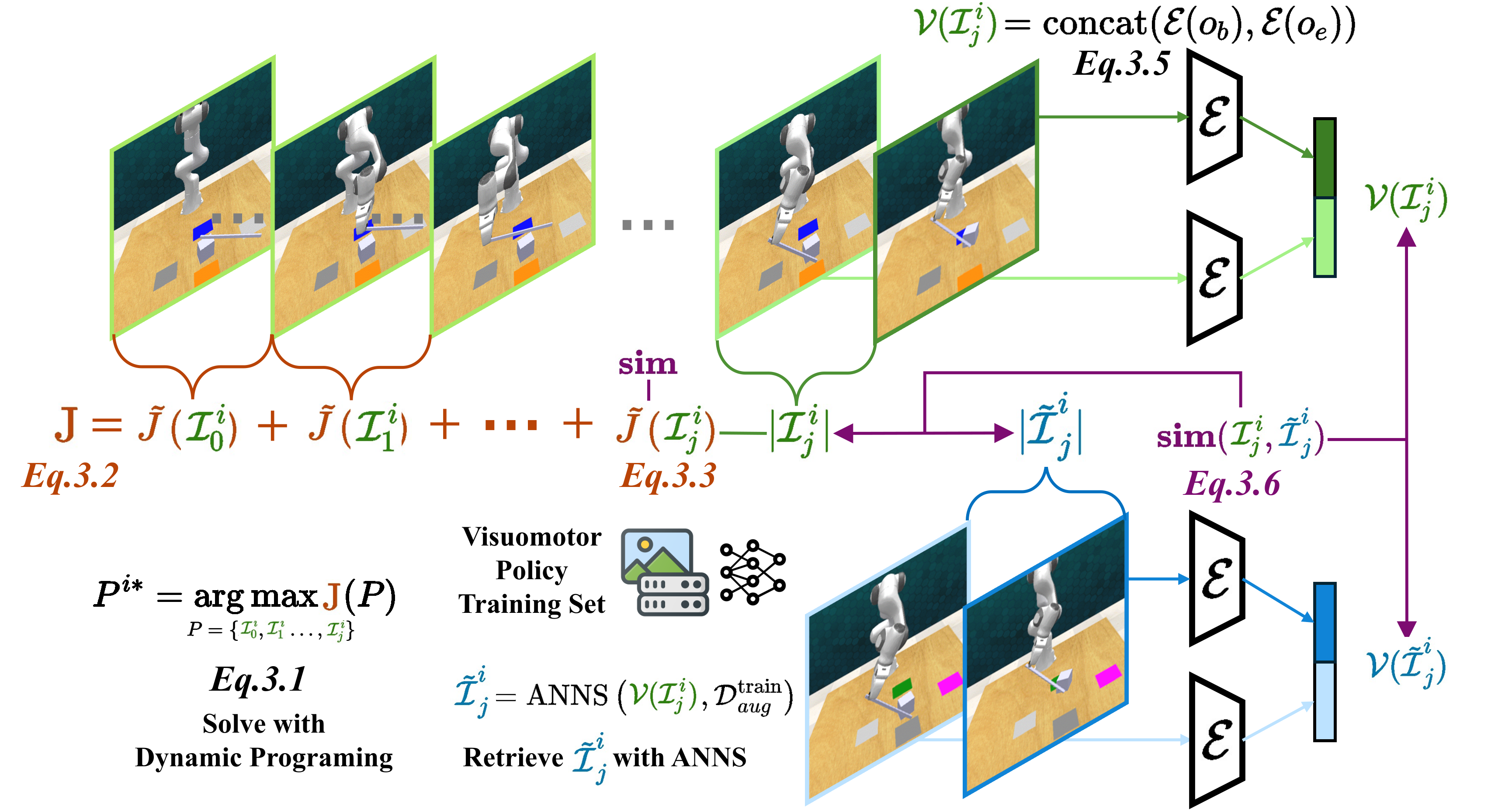
RDD formulates demonstration decomposition as an optimal partitioning problem, using retrieval with approximate nearest neighbor search (ANNS) and dynamic programming to efficiently find the optimal decomposition strategy.
Improves End-to-End Performance of Hierarchical VLA
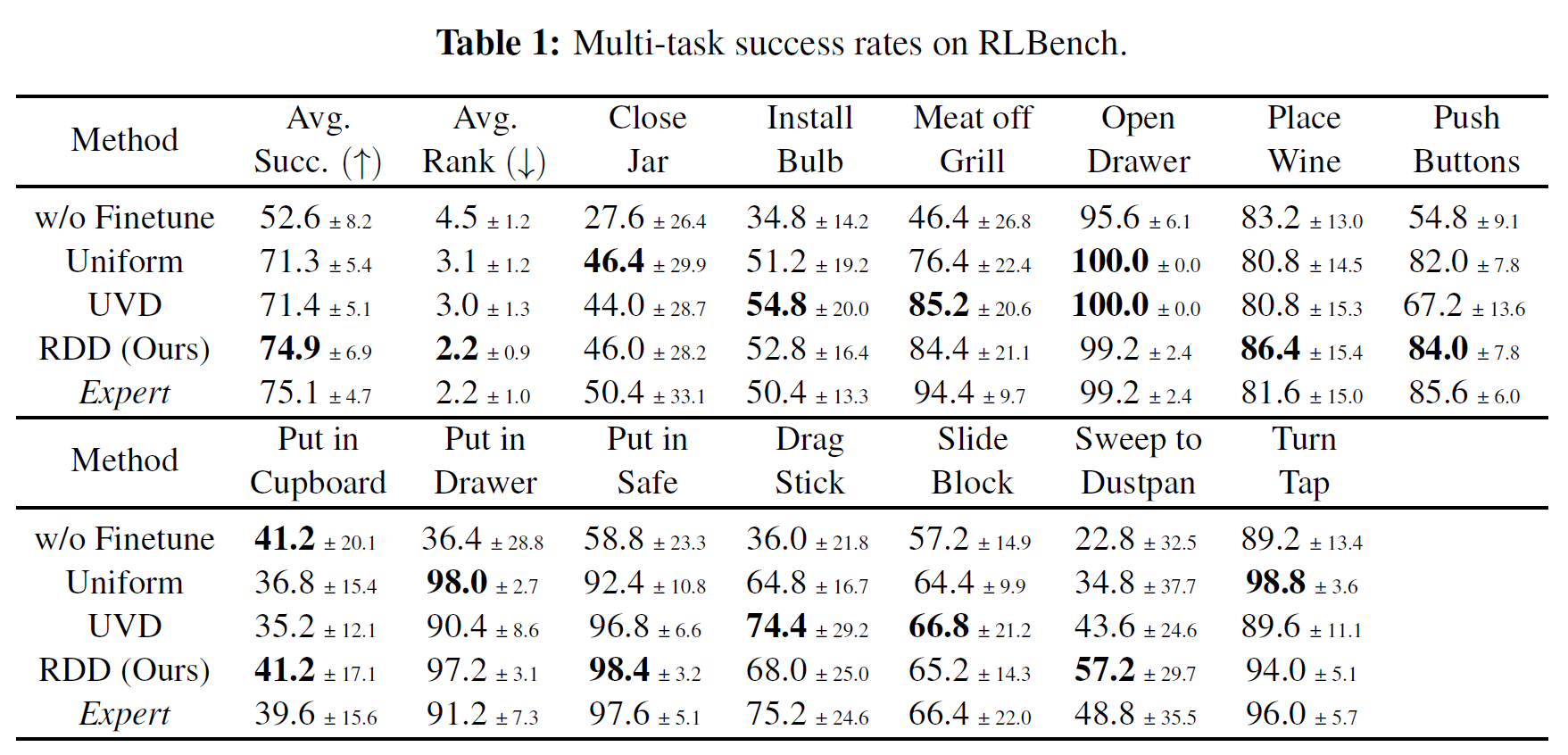
Results are averaged over 10 random seeds. RDD improves the end-to-end performance of the hierarchical VLA RACER and achieves a near-oracle performance and only compromises the success rate of merely 0.2% compared with the expert decomposer
Real-World & Out-of-Distribution Demonstrations
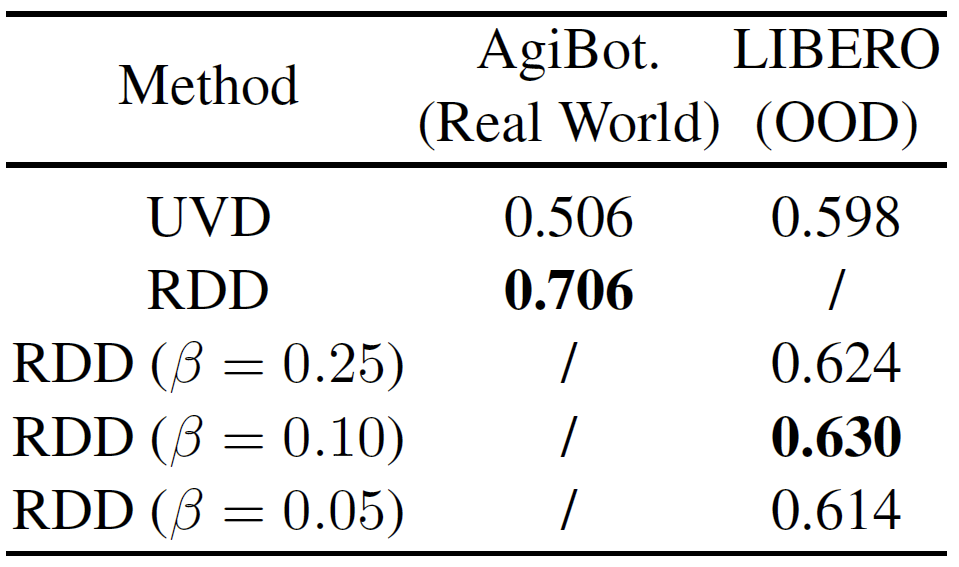
Performance (IoU) on AgiBotWorld-Alpha (real-world) and RoboCerebra (out-of-distribution sub-tasks)
Scalability
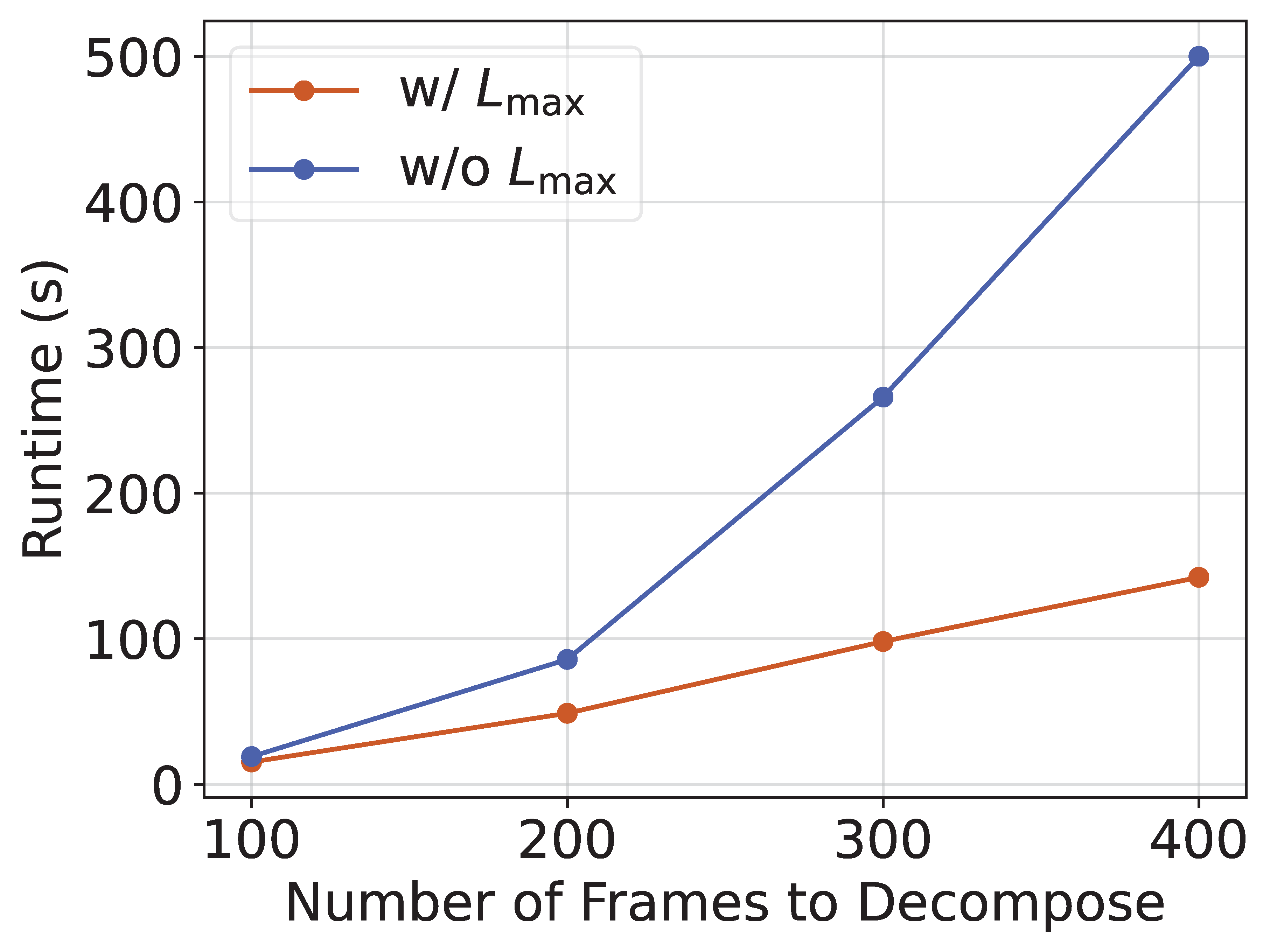
Linear time complexity of RDD with bounded maximum sub-task duration. Experiment uses a single CPU core (AMD EPYC 9254). We also provide a conceptual speed evaluation of RDD when working with the GPU-accelerated ANNS method FAISS. For details please refer to our paper.
BibTeX
@inproceedings{yan2025rdd,
title={RDD: Retrieval-Based Demonstration Decomposer for Planner Alignment in Long-Horizon Tasks},
author={Yan, Mingxuan and Wang, Yuping and Liu, Zechun and Li, Jiachen},
booktitle={Proceedings of the 39th Annual Conference on Neural Information Processing Systems (NeurIPS)},
year={2025},
}